
How Can I Choose an Explainer? An Application-grounded Evaluation of Post-hoc Explanations
ACM Conference on Fairness, Accountability, and Transparency (FAccT 2021), 2021
Abstract
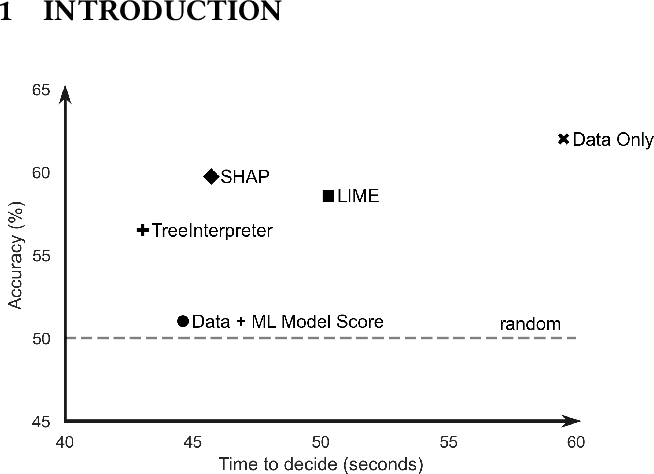
There have been several research works proposing new Explainable AI (XAI) methods designed to generate model explanations having specific properties, or desiderata, such as fidelity, robustness, or human-interpretability. However, explanations are seldom evaluated based on their true practical impact on decision-making tasks. Without that assessment, explanations might be chosen that, in fact, hurt the overall performance of the combined system of ML model + end-users. This study aims to bridge this gap by proposing XAI Test, an application-grounded evaluation methodology tailored to isolate the impact of providing the end-user with different levels of information. We conducted an experiment following XAI Test to evaluate three popular post-hoc explanation methods -- LIME, SHAP, and TreeInterpreter -- on a real-world fraud detection use case, with real data, a deployed ML model, and fraud analysts as subjects. Our results show that showing Data Only results in the highest decision accuracy and the slowest decision time among all variants tested. All three explainers improve accuracy over Data + Model Score but LIME was the least preferred by users, probably due to its substantially lower variability of explanations from case to case.