
Bayesian Evaluation of Blackbox LLM Behavior
NeurIPS 2025 LLM Evaluations Workshop, 2025
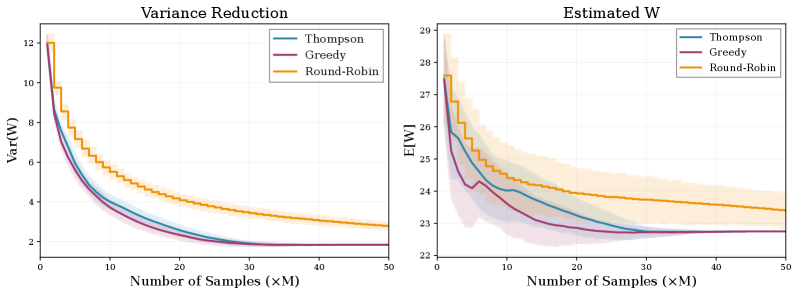
Abstract
It is increasingly important to evaluate how text generation systems based on large language models (LLMs) behave, such as their tendency to produce harmful output or their sensitivity to adversarial inputs. Such evaluations often rely on a curated benchmark set of input prompts provided to the LLM, where the output for each prompt may be assessed in a binary fashion (e.g., harmful/non-harmful or does not leak/leaks sensitive information), and the aggregation of binary scores is used to evaluate the LLM. However, existing approaches to evaluation often neglect statistical uncertainty quantification. We provide background on LLM text generation and evaluation, and describe a Bayesian approach for quantifying uncertainty in binary evaluation metrics. We focus in particular on uncertainty induced by the probabilistic text generation strategies typically deployed in LLM-based systems. We present two case studies: (1) evaluating refusal rates on a benchmark of adversarial inputs, and (2) evaluating pairwise preferences of one LLM over another on open-ended dialogue examples.